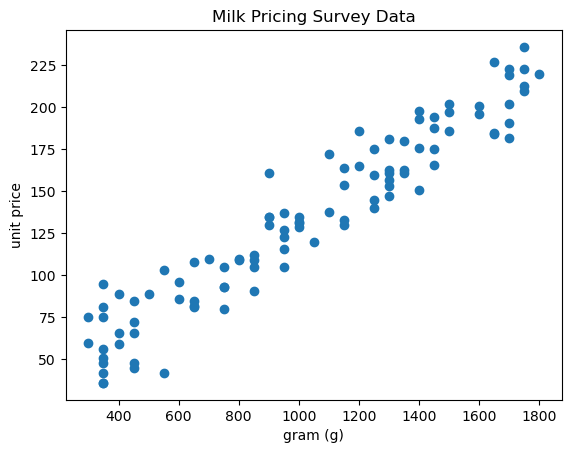
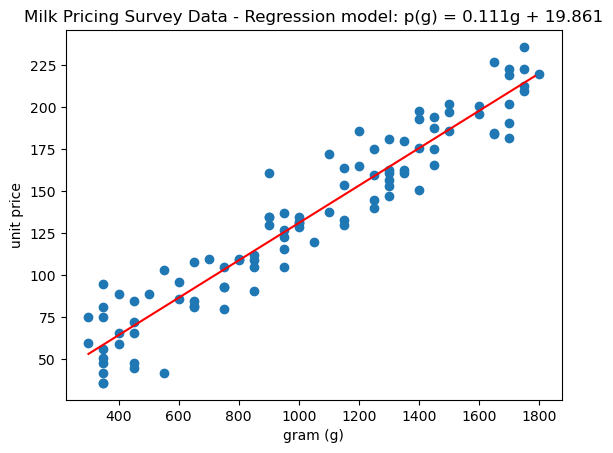
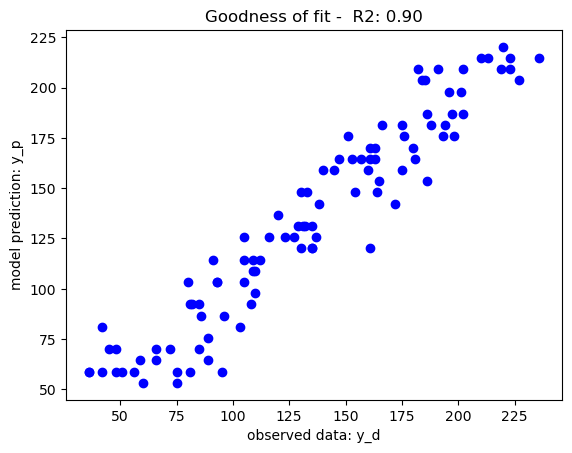
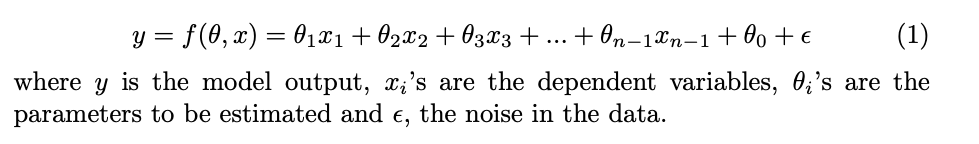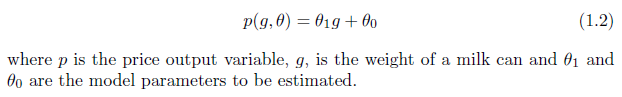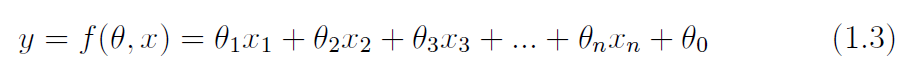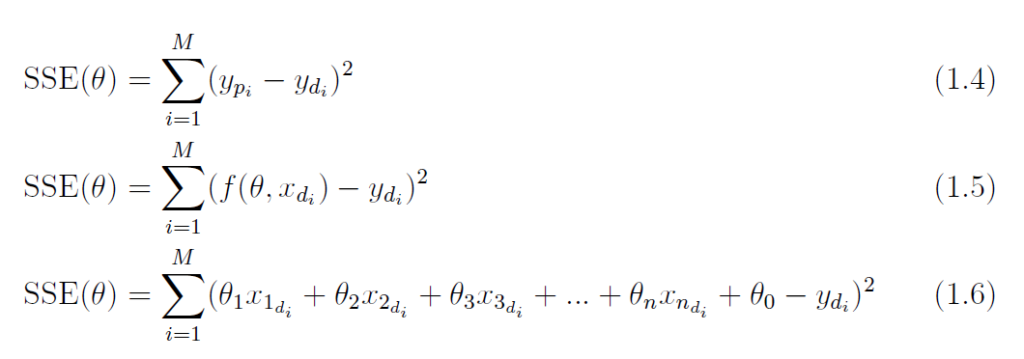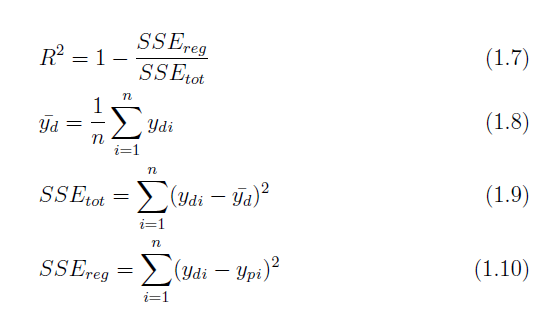To evaluate the goodness of fit for a regression model, a scatter plot displaying observed data and model predictions is often created, accompanied by the coefficient of determination score R2. A well-fitted model will yield a stronger correlation between observed data and the model prediction.